PostgreSQL Database Based Distributed Lock
• • ☕️ 6 min readDistributed Systems
Many teams across different companies started using cloud infrastructure extensively, and cloud computing popularity in business continue to grow. Industry experts predicts that market will grow over $200 billion in 2020, that is one of the rapid advancement in IT throughout the recent years. A Clear indication that, with investments increasing in cloud computing so the need for new tools. Most known trio of cloud platforms; Amazon Web Services (AWS), Microsoft (Azure), Google Cloud (GC).
Distributed Lock
Concurrency and non-determinism are the biggest reasons that multi-threading programming is a pain. When there are multiple threads two different threads may try to write on the same piece of memory region, to prevent this traditionally mutual exclusivity is used where OS signals when critical sections of code need exclusive access. In a conceptual sense, distributed locks are similar to the multi-threading locks, only difference is; threading locks take place on machine itself, whereas distributed locks take place within the environment, in my experiment cloud database (AWS-Postgres). I like to think distributed locks like a remote-controller of TV, at a time only 1 thread holds the controller(lock), similar to holding a remote controller in your family, that will determine who will watch what and what next.
Distributed Solutions
Of course as always, there has been different approaches to solve this determinism issue for multi-jobs, such as:
ZooKeeper: In a nutshell zookeeper gives you ability build server applications by creating master, worker, worker (at least 3 processes required). And the zookeeper manages who will be the next master if master is down, or which worker does work at a time. Most common problem in this approach is leader-worker election in different scenarios, as nicely stated in this article: https://www.embedded.com/distributed-software-design-challenges-and-solutions/
Using 3rd Party Lock Holder: In this approach you can use either a database or file to determine and hold/release a lock. Biggest challenge in this solution is
ensuring the atomicity of operation, because you need to make sure only 1 guy has the remote controller and power of change the channel (modifying resources). To ensure data always accurate, there must be only one process in server fleet to modify the shared resource. There is also some protocols to solve this problem but I found they are little bit too complex for my case (eg. Raft, Paxos). Nevertheless, I will leave couple links for future exploration.- Raft: https://raft.github.io/
Postgres based lock
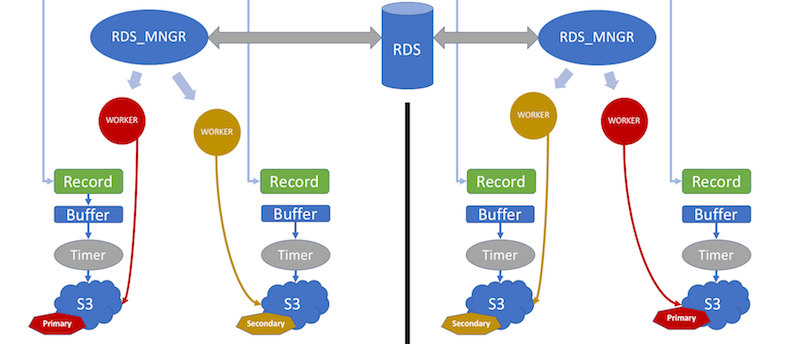
To do this experiment I set up two different machines, and each have database access.
And I used pg_advisory_lock to create a unique lock with unique lockid, so each time primary or secondary workers access to table for RMW (read-modify-write)
they have to acquire the pg_lock, and every time they are done, the they should release the lock.
Ingredients:
- 2 EC2 instances
- Each Instance have 2 S3 Workers (Where they write to the same resource S3)
- Writers (workers) run on timers (to test functionality)
- S3 Workers distinguished as Primary / Secondary
- Only Primary Worker has ability to Write, while Secondary Worker always
checks onif Primary is Down
To write modify the shared resource (S3 File), each worker should know about what each other’s doing.
For the same S3 topic, only one instance at a time should be active as
Primary.
In the C++ code I also wanted to wrap advisory lock call to a class, in order to effectively destroy the lock similar to this;
// lock functions
void lock(const int lockid) const ;
void unlock(const int lockid) const ;
// RAII style lock wrapper
class lockguard {
public:
explicit lockguard(const psqldb::PsqlDb* ptrdb, const int lockid) :
ptrDb_(ptrdb), lockid_(lockid) {
// lock on construction
ptrdb->lock(lockid_);
}
~lockguard() {
ptrDb_->unlock(lockid_);
}
private:
lockguard(const lockguard&) = delete; // delete this
const psqldb::PsqlDb* ptrDb_;
const int lockid_;
};
In code when you want to acquire the lock you need to pass 2 paramaters;
- database pointer which connection in session
- lockid. This lockid should be the
samefor the workersdoing the same jobmeaning the processes trying to access the same resource (in our case AWS-S3 File) And whenever the lockguard unlocked / or destroyed (goes out of scope) lock will be released.
In Action
Basically workflow as follows in Database by leveraging PostgreSQL:
RDS Manager is responsible of database connection and employing workers for each S3 recorder. Worker is responsible to execute the policy in time intervals (Primary-Secondary). Each Worker uses the same database connection through RDS_manager, Rds manager has its own Queue put transactions in order.
- Make sure database connection credentials set correctly, some information similar to this;
[postgredb]
host=exampleEndPoint.com (AWS endpoint)
dbname=exampleDatabase
port=xxxx (5432 default)
user=exampleuser
password=xxxxxx
- Make sure each machine has UNIQUE name, AWS IAM, or AWS IP ADDR etc.
- lockid: Make sure each S3 recorder has UNIQUE lockid as integer between 1–998 (999 Reserved for Create, Insert Table Records)
- If this is true, all the config files on all other instantances/machines should be false for this specific recorder, otherwise thaty will create contention (First Come First Server Basis)
- Each Machine insert into
info_recorderstable itsname/time/num_primary/num_secondaryinformation, then starts its ownprimary & secondary recorders - Workers check database every
0.5 seconds (500 Milliseconds) - Primary Updates
Time & Primary Upevery0.5 seconds - Secondary Checks
Time || Primary Downevery0.5 seconds If2 seconds of time elapsed,Secondary takes over- If Primary Down for
any reason, all of the locks released on database level (pg_advisory_lock) - Primary and Secondary workers locks only their own level of record by lockid when executing
DB Read || Write commits - Primary and Secondary should have identitical config files except the fields
machinenameand their respective recorders asprimary=trueorprimary=false
Why pg_advisory_lock in PostgreSQL?
In this example session level pg_advisory_lock used, good thing about this type of lock is when the connection goes down, or instance dies
lock is released by itself without needing to interact with postgresql, to dodge deadlock situation.
You can also read about advisory locks in detail here: https://vladmihalcea.com/how-do-postgresql-advisory-locks-work/
Conclusion
Postgres lock table works with a good-design, and it is cost-efficient, basically rather than using 3 machines / instances you can leverage PostgreSQL lock-table as main communication point.
But every step of locking process and lock time intervals should be well-thought.
I just experienced only 2 workers and only and 1 writer at a time, however for more multi writers things gets complicated real-fast and
lock-table & write-policy, reader-election design gets more difficult.