Road Sign Recognition with Raspberry Pi
• • ☕️☕️☕️ 15 min read
Intro
The field of traffic sign recognition is not very old with the first paper on the topic published in Japan in 1984 when the aim was to try computer vision methods for the detection of objects. Since then however, the field has continued to expand at an increasing rate
Traffic sign recognition is used to maintain traffic signs, warn the distracted driver, and prevent his/her actions that can lead an accident. A real-time automatic speed sign detection and recognition can help the driver, significantly increasing his/her safety. Traffic sign recognition also gets an immense interest lately by large scale companies such as Google, Apple and Volkswagen etc. driven by the market needs for intelligent applications such as autonomous driving, driver assistance systems (ADAS), mobile mapping, Mobileye, Apple, etc. and datasets such as Belgian, German mobile mapping
Methods of recognizing and detecting traffic signs continue to be published as the number of systems and tools to interpret images increases across multiple platforms.

This work focused on a low cost, off the shelf solution, specifically, a mini embedded computer Raspberry Pi, that is capable of doing everything you would expect a desktop computer to do, from word processing, image processing to playing games. The system has originally been developed by Raspberry Pi Foundation in an effort to give young people an easy solution to learn coding and computer programming. Raspberry Pi Foundation was founded in 2009, by a game developer David Braben, and supported by a tech firm, Broadcomm, and the University of Cambridge Computer Labs
In order to provide fast processed results, this project aimed to demonstrate use the of simple shape recognition algorithms and open source optical character recognition (Tesseract OCR) on Raspberry Pi. Tesseract OCR is an open source optical character recognition module for various operating systems. And its development supported by Google since 2006. Tesseract OCR is one of the top character recognition engines in terms of accuracy. Tesseract can detect letters in various forms of images, and it uses the open source C library Leptonica library. In this project we will be able to pass images to Tesseract OCR and read them. To improve accuracy we had to do pre-processing on images before pass them Tesseract OCR engine. The system can be scaled down to improve the conditions of highly automated driving systems.
Method
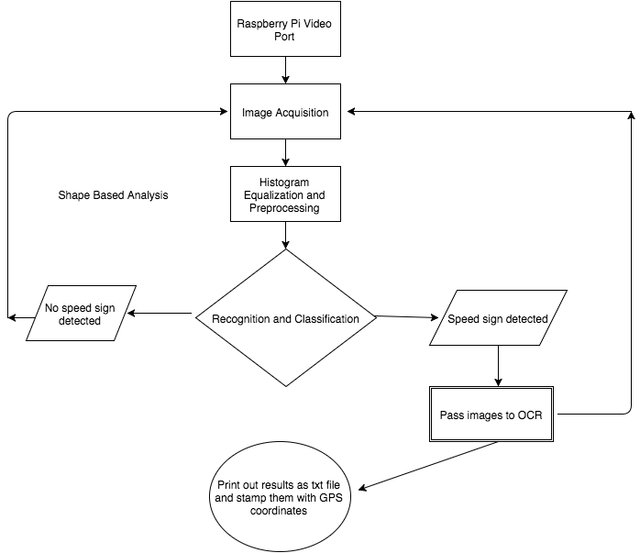
To design a good recognition system, the system needs to have a good discriminative power and a low computational cost. The system should be robust to the changes in the geometry of sign (such as vertical or horizontal orientation) and to image noise in general. Next the recognition should be started quickly in order to keep the balanced flow in the pipeline of Raspberry Pi allowing for processing of data in real time. Finally, the optical character recognition engine must be able to interpret a pre-processed image into a text file. The identification of the speed signs is achieved by two main stages: detection and recognition. In the detection phase the image is pre-processed, enhanced, and segmented according to sign properties such as color, shape, and dimension. The output of segmented image contains potential regions, which can be recognized as possible speed signs. The effectiveness and speed are the important factors throughout the whole process, because capturing images from the video port of Raspberry Pi and processing images as they come into to the pipe should be synchronized. In the recognition stage, each of the images is tested with K-Nearest algorithm according to their dimensions, which is an important factor to detect the speed signs, since we want to process images only once as they come, it also emphasizes the differences among the other rectangle shapes. The shape (rectangle) of the signs plays a central role in this stage. When a speed sign detected, it is passed into the optical character recognition engine to be converted and written out as a text file. The GPS module is used to add to the results with time and location. To retrieve GPS data and write them into text file another open source platform Arduino-Uno used. This platform consists of both a physical programmable circuit board (micro-controller) and its integrated development environment (IDE). Arduino was used for this project because, unlike most complex programmable circuit boards, the Arduino does not need a separate piece of hardware to program instead, the only thing it needs a USB cable to load new code onto the board
CapturingImages
A Raspberry Pi is capable of capturing a sequence of images rapidly by utilizing its video- capture port with JPEG encoder. However several issues need to be considered:
- The video-port capture is only capturing when the video is recording, meaning that images may not be in a desired resolution/size all the time (distorted, rotated, blurred etc.).
- The JPEG encoded captured images do not have exif information (no coordinates, time, not exchangeable).
- The video-port captured images are usually “more fragmented” than the still port capture images, so before we go through pre-processed images we may need to apply more denoising algorithms.
- All capture methods found in OpenCV (capture, capture_continuous, capture sequence) have to be considered according their use and abilities. In this project, the capture_sequence method was chosen, as it is the fastest method by far.
Using the capture sequence method our Raspberry Pi camera is able to capture images in rate of 20fps at a 640×480 resolution. One of the major issues with the Raspberry Pi when capturing images rapidly is bandwidth. The I/O bandwidth of Raspberry Pi is very limited, and the format we are pulling pictures makes the process even less efficient. In addition, if the SD card size is not large enough, the card will not be able to hold all pictures that are being captured by camera port, leading to cache exhaustion.
Multi-threading in Capturing and Processing Images
Because of limited I/O Bandwidth of the Raspberry Pi, structuring the multi-threading is an extremely important initial step of the pre-processing algorithm for images. To succeed this first we need to capture an image from the video-port then process. Raspberry Pi maintains a queue of images and process them as the captured images come in. Most importantly, the Raspberry Pi image processing algorithm must run faster than the frame rate of capturing images, in order to not to stall the encoder
In addition, special care must be taken to ensure proper synchronization. Here the GIL (Global Interpreter Lock) is difficult to use in Python compared to low-level languages’ multithreading. Python is an interpreted language thus, the interpreter is not able to execute code aggressively, because interpreter does not see the Python script as whole program. This means other than that the algorithm within the Python, to account for processing speed, we must rely on how fast interpreter works. Additionally developing a multi-threaded application becomes more complex rapidly in both developing and debugging compared to its single-threaded counterpart. In our schools we learn a mental model well suited for sequential programming that just does not match the parallel execution model. In this case the Global Interpreter Lock is really helpful to ensure consistency between the way of our thinking and between threads. Technical details about GIL can be researched by CPython repository
Detecting Speed Signs

When we look at the pictures of speed signs, the most defining feature of a speed sign is rectangular shape with mostly round edges. Before finding the rectangles in a captured image, we retrieve the contours, thus the shape detection algorithm employed loops through a subset of contours and checks if the contour shape is rectangle. The shape detection is based on the OpenCV’s Python implementation preceded by filtering and edge detection. To prevent the noise from being mistaken as edges, and produce wrong results, the noise must be reduced to certain level. Thus, the images can be smoothed by applying Gaussian Filter.
Open CV Contour Features and Edge Detection

The purpose of the edge detection is to significantly reduce the amount of data in the image by converting the image into binary format. Even though Canny edge detection is quite an old method, it has become one of the standard edge detection algorithms. In doing image processing and especially shape analysis it is often required to check the objects shape, and depending on it perform further processing of a particular object. In our application it is important to find the rectangles in each of frames as these may potentially correspond to road speed signs. This shape detection must be done at least once in every 40 frames to ensure close to real processing. Once we check all the contours retrieved, we should look for closed loops then that closed loop should meet the following conditions to become a rectangle. Contour approximation is an important step for finding desired rectangles, since because of distortions other issues in the image perfect rectangle may not be visible. The contour approximation might be in this case better choice for finding convex hulls. After this step we can approximate the rectangular shape in the captured image as shown in Figure 2. Once the individual regions for the signs are identified, they are rotated to fit a common alignment and then OCR is performed. To align the signs that first we find 4 max and min points in a rectangular shape.
Application
k-NearestNeighborAlgorithm(kNN)
The kNN algorithm is a non parametric, basic algorithm, that does not make assumptions on the underlying data distribution such as Gaussian mixtures etc. For kNN it is assumed that the given data is in a feature space (geometrical metric space) and the points are in a 2D geometrical space, where they have a notion of distance [11,18]. Each of the training data consists of a set of vectors and classes assigned to each vector. k stands for number of neighbors that influences the classification and is usually an odd number.
Open Source Optical Character Recognition Engine
In order to read the speed signs accurately, Tesseract Optical Character Recognition (OCR) is chosen for the project. Tesseract OCR is and open source engine started as PhD research project at the HP Labs, Bristol. After a joint project with HP Bristol Labs and HP scanner division, Tesseract OCR was shown to outperform most commercial OCR engines. The processing within Tesseract OCR needs a traditional step-by-step pipeline. In the first step the Connected Component Analysis is applied, and the outlines of the components stored. This step is particularly computational intensive, however it brings number of advantages such as being able to read reversed text, recognizing easily on black text on white background. After this stage the outlines and the regions analyzed as blobs. The text lines are broken into characters cells with the algorithm nested in the OCR for spacing. Next, the recognition phase is set two parts. Each word is passed to an adaptive classifier, and the adaptive classifier recognizes the text more accurately. Adaptive classifier has been suggested for use of OCR engines in deciding whether the font is character or non-character. Like most of the OCR engines Tesseract does not employ a template (static) classifier. The biggest difference between a template classifier and an adaptive classifier is, that adaptive classifiers use baseline x-height normalization whereas static classifiers find positions of characters based on size normalization. The baseline x-height recognition allows for more precise detection and recognition of upper case, lower case characters and digits, but it requires more computational power in return.
To improve quality of results, the images ideally should be given to the OCR module in form of clear black text and white background. By default Tesseract OCR applies Otsu’s thresholding method to every image, however since we have our custom pre-processing algorithm, this step was bypassed in order to improve speed. To disable internal thresholding of Tesseract OCR; the tesseract delegate option should be set as “self”(tesseract.delegate = self).
Conclusion
The system was built on a Rasberry Pi board running Linux and Python / Open CV Libraries. A custom made case was created. The system also included a camera and a GPS module. A version of Snappy Ubuntu Core is available as Ubuntu MATE for the Raspberry Pi and can be downloaded from Ubuntu Mate official website [14]. All compatible versions of Linux on Raspberry Pi including Red Hat, Mandrake, Gentoo and Debian can be used, however, since in this project GPIO pins on Raspberry Pi were extensively used for camera module and USB WiFi-dongle, Raspbian OS was chosen. Raspbian is a Debian based Linux distributed de-facto standard operating system, which comes with pre-installed peripheral units libraries (GPIO, Camera Module). It is jointly maintained by the Raspberry Pi Foundation and community. It also has raspi-config, a menu based tool, that makes managing Raspberry Pi configurations much more easier than other operating systems, such as setting up SSH, enabling Raspberry Pi camera module etc.
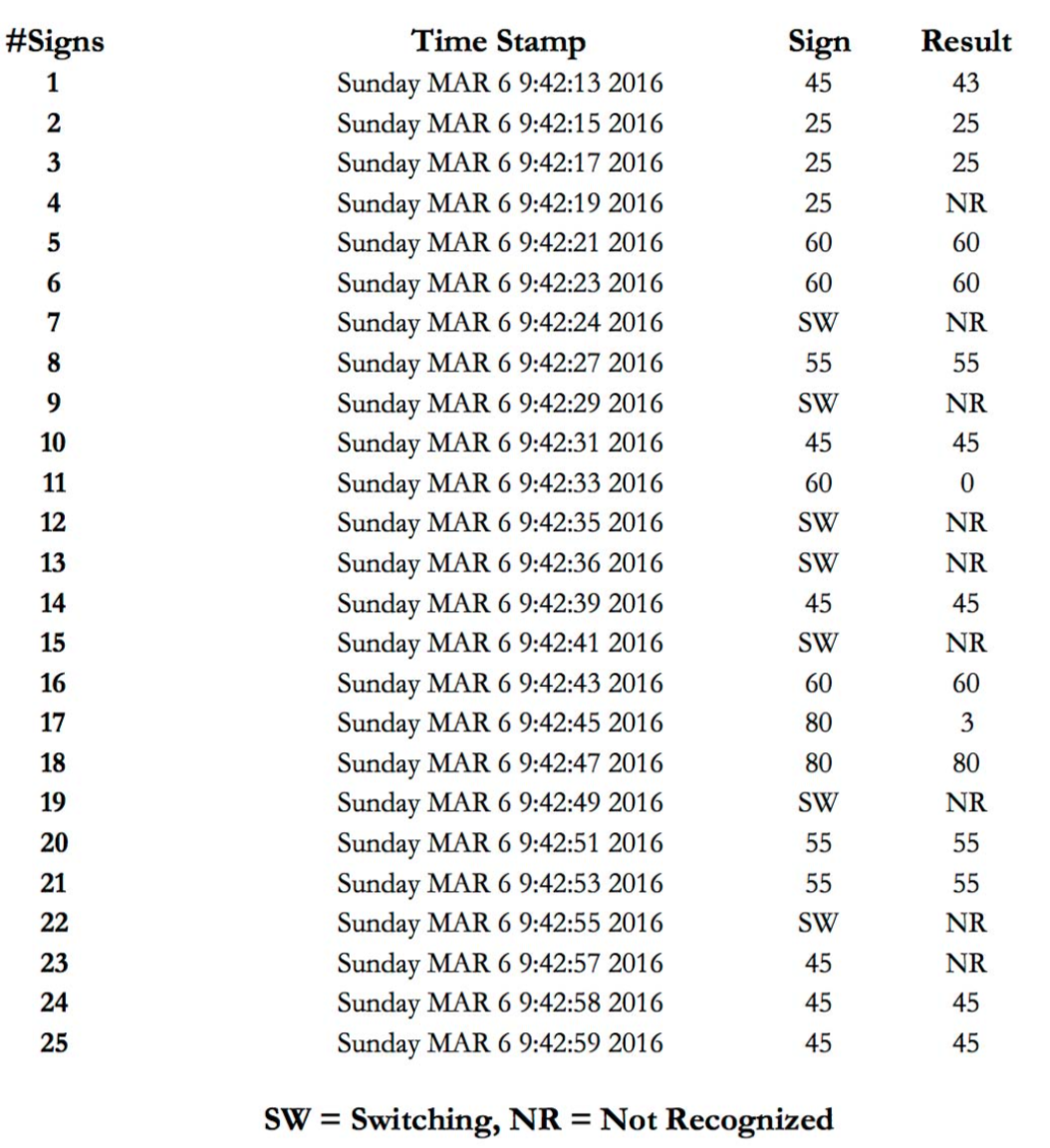
For the experiments, the system was presented with signs printed on paper. Once the image processing of the sample image set is complete, the results can be compared to the actual speed signs (see Figure 5). Many practical observations were gained while performing data collection and analysis. It was obvious that while the software was robust and capable of detecting speed signs, the corner of the speed signs were misinterpreted by Tesseract OCR in some cases.
The sign column contains the speed on the sign currently shown to the system, or SW if the frame collection was done while the signs were switched. The results column has the values of the signs as recognized by the system. Although most speed signs in I/O stream of Raspberry Pi are detected at the detection stage, there are some misinterpretations such as V25, T80, 60L etc. Misinterpretation usually occurs when the speed signs are rotated or the Tesseract OCR converts corner of the frames into letters. After the cropping algorithm applied on pre- processed images, and adding a delay between the frames (delay between processing and reading images from stream) the system reached 80% accuracy. The performance of the developed algorithm, however, may be affected by several parameters, including lightning conditions, background noise etc. The system is able to read different road signs as long as they are rectangular shape therefore it can be extended to accommodate new speed signs. 'The processing time in Raspberry Pi is around 1–2 seconds.
Outcomes of the system:
- The algorithm which has been implemented is quite accurate but very slow, the total average time for both detection and recognition is ~1.5 frames per second (fps) on a 700 MHz Broadcom chip.
- The detection phase is based on the shape, and runs faster than recognition, that causes an increase of the images available for processing. To prevent errors caused by prior images, the processor should be stalled for a small time period.
- Because of shape based detection, the biggest issue is the presence of obstacles close to the speed signs.
- Python-OpenCV is a wrapper around the original C/C++ code, which makes it simple and fast. But native Python script written functions that do not exist within OpenCV (our own functions in Python), reduces performance drastically.
Future
The work described here is split into two parts, similar to other applications in the field, as “detection” and “recognition”. For the detection part, shape-based algorithms were used because color-based segmentation is much less reliable than shape-based segmentation. In similar cases to speed sign detection, they were many different techniques used, such as genetic algorithms, Hough transforms, and artificial neural networks based algorithms. Due to limited computation power of Raspberry Pi, complex techniques were not chosen despite their availability within the OpenCV libraries (such as Eigen faces, SURF-SIFT template matching, and Fuzzy matching). In order to keep Raspberry Pi running smoothly, other classifiers like k nearest neighbor, and Euclidian distance were chosen for this project. Speed sign detection in different conditions like lighting, disorientation was not tested well. By using a pre-built OCR engine, a detailed study of recognition techniques is outside the scope of this paper. Detection, tracking and recognition are interwoven, while recognition reduces false positives and detection narrows the choices and increases accuracy of a system. Keeping the results is another important part; as a result, it needs to be improved as more databases are being developed by the time. This project’s implementation focused on real-time video processing, however, for future work, the use of car’s dynamics (direction, trajectory, speed changes etc.) should be considered to improve the system’s robustness of the speed sign reading process. A comparison of the performance within an embedded system of this project will provide the baseline of the improvements. However, the lack of an open source evaluation framework for similar systems (datasets for speed signs, labeled data etc.) makes it hard to perform that comparison. Our work supports claims that the complexity of traffic sign recognition systems will continue to be reduced in the near future as embedded technology advances.
Long Live Raspberry Pi!